In January, I attended the Developers for Development hackathon in Montreal hosted by the Canadian Department of Foreign Affairs, Trade and Development. Launching headlong into 36 hours of software development fueled by tea, adrenaline and very little sleep, we hoped to tackle a challenge that has long stymied the open data community – how do we reliably extract structured data from unstructured text? Debuting an automated coding program called ‘Robocoder,’ we asked developers to help us improve upon an early prototype that applies activity codes to aid activities based on text descriptions.
Activity codes are a more granular level of sector and purpose codes used to track and organize information. For example, instead of just coding targeted aid funding to combat malaria or respiratory disease to a catchall category such as "12250 - Infectious & Parasitic Disease Control," we can code projects to specific subcategories as "12250.03 - Malaria control" or "12250.07 - Acute respiratory infections." These granular distinctions allow a researcher or policymaker to more easily filter information to focus in on the specific types of projects of interest to them. (Note: This 2012 Center for Global Development post by Amanda Glassman speaks to the importance of this type of coding.)
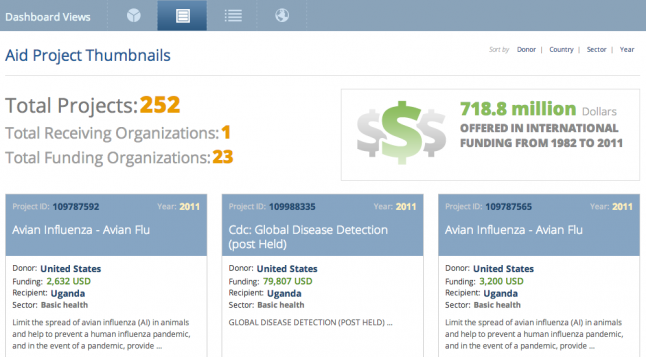
The above image represents search results from AidData's Advanced Search function when looking for projects under the "Infections and Parasitic Disease Control" sector in Uganda, totaling 252 projects.
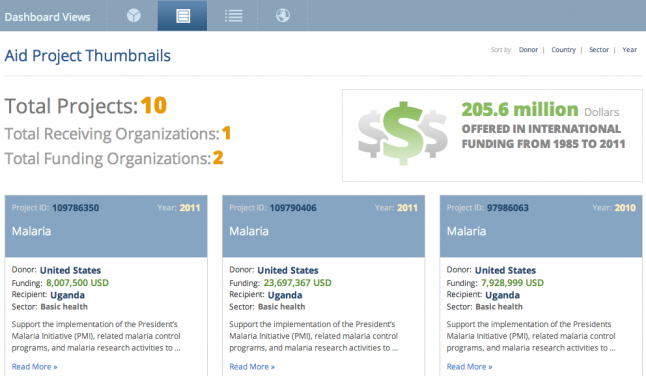
The above image represents search results from AidData's Advanced Search function when looking for projects assigned a "Malaria Control" activity code in Uganda, totaling 10 projects. Both sector code searches and activity code searches render useful information to researchers, but one allows for a more general search while the other allows for a more refined search.
The activity coding process we currently use produces incredibly high quality data created by humans. However, producing codes this way is time and resource intensive, especially when compared to a computer that could process a million projects in one day. We wanted to see how reliably we could automate the process of coding to make it faster and cheaper without sacrificing quality. To that end, the AidData team built Robocoder – an automated coding program that uses 1.3 million projects that were previously coded manually as 'training' data to predict the codes for future projects.
In developing Robocoder, we have taken the following approach:1. Build a weighted dictionary of words and activity codes by looking at all previously coded projects.2. Use the term frequency–inverse document frequency approach to find the most important words in unstructured text.3. Aggregate the weighted codes for all of the important words, and select the most likely activity codes.4. Build tests that compare Robocoder's results with already coded projects.5. Tweak algorithm and rerun tests; rinse and repeat.
The hackathon competition offered a way to get more eyeballs on Robocoder and continue to refine the prototype. We made some great strides, as working with these other developers enabled us to increase Robocoder’s success rate from 6 percent to 30 percent in just two days.
Unfortunately, we quickly hit a ceiling. Right now, our method is not yet reliable enough to replace or augment our human coders. But the improvements in Robocoder’s success rate suggests that, with a little more time, we could build a tool that would effectively support and accelerate our human coding.
The biggest barrier in moving forward is accurate natural language processing that even the likes of Google Translate still struggles to change accurately. Fortunately, natural language processing and data extraction is not exclusive to international aid data, and we can leverage many existing open libraries and algorithms. (Note: If you’re interested in natural language processing, check out some additional resources at the end of this post.)
At AidData, we’re going to build upon the contributions of our fellow developers and keep iterating the Robocoder prototype. We’d love to have you join us in this effort. Check out the github repo to learn more about the Robocoder challenge and our test data.